
第十四讲 指令周期和指令流水线
指令周期
处理单个指令的过程
- 取指周期:从内存中提取一条指令
- 执行周期:执行所提取的指令
- 间址周期: 把间接地址的读取看成是一个额外的指令子周期
CPU的任务
- 取指令:CPU必须从存储器(寄存器、cache、主存)读取指令
- 解释指令:必须对指令进行译码,以确定所要求的动作
- 取数据:指令的执行可能要求从存储器或输入/输出(I/O)模块中读取数据
- 处理数据:指令的执行可能要求对数据完成某些算术或逻辑运算
- 写数据:执行的结果可能要求写数据到存储器或I/O模块
CPU需求: 寄存器
- 在指令周期中临时保存指令和数据
- 记录当前所执行指令的位置,以便知道从何处得到下一条指令
- MAR: 存储地址寄存器
- MDR/MBR: 存储数据寄存器/存储缓冲寄存器
- PC: 程序计数器
- IR: 指令寄存器
指令流水线
- 一条指令的处理过程分成若干个阶段,每个阶段由相应的功能部件完成
两阶段方法: 取指令和执行指令
- 在当前指令的执行期间取下一条指令
- 问题:执行时间一般要长于取指时间
- 问题: 主存访问冲突
- 问题: 条件分支指令使得待取的下一条指令的地址是未知的
为了进一步的加速, 流水线必须有更多阶段
六阶段方法
- 取指令 FI
- 译码指令 DI
- 计算操作数 CO
- 取操作数 FO
- 执行指令 EI
- 写操作数 WO
- 各个阶段所需时间几乎相等
- 不是所有指令都需要这六个阶段
- 不是所有的阶段都能并行完成
- 限制: 条件转移指令能使若干指令的读取变为无效
- 限制: 中断
流水线性能的计算
ti: 流水线第i阶段的电路延迟时间
tm: 最大段延迟(通过耗时最长段的延迟)
k: 指令流水线段数
d: 锁存延时(数据和信号从上一段送到下一段所需的段间锁存接收时间)
执行一条指令的周期时间 t = max(ti) + d = tm + d注意这里为什么只是一个锁存延时, 因为计算的是这次指令结束后, 到下一条指令开始的间隔, 其他段间间隔会被tm覆盖
执行n条指令总时间 T = (k + n-1) * t注意这里为什么是k + n-1, 因为最后一条指令的时候, 已经没有新的指令进来了, 它的时间就是执行k阶段的耗时, 没有并行执行(因为只有它一条指令)
加速比: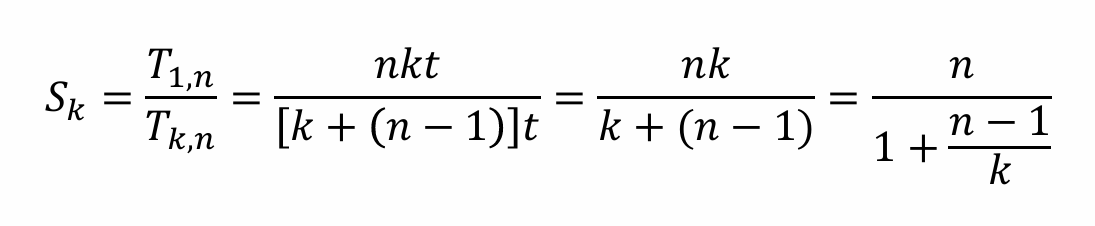
只有一段的T/k段的T nkt/(k+n-1)t注意这里为什么分子还有k, 因为这里用的t是第i段的电路延迟时间, 当只采用一段的情况, 完成一条指令还是需要那么多时间的, 变化只发生在完成多条指令的时候
误解:
流水线中的阶段数越多,执行速度越快
解释:
- 在流水线的每个阶段,将数据从一个缓冲区移动到另一个缓冲区以及执行各种准备和传递功能都涉及一些开销
- 处理内存和寄存器依赖以及优化管道使用所需的控制逻辑数量随着阶段的增加而急剧增加
冒险: 在某些情况下,指令流水线会阻塞或停顿(stall),导致后续指令无法正确执行
- 结构冒险/硬件资源冲突
- 数据冒险/数据依赖性
- 控制冒险
结构冒险
- 原因:已进入流水线的不同指令在同一时刻访问相同的硬件资源
- 解决:使用多个不同的硬件资源,或者分时使用同一个硬件资源
数据冒险
- 原因: 未生成指令所需要的数据
- 解决
- 插入nop指令:可以延迟后续指令的执行,直到所需的数据准备就绪
- 插入bubble:类似于nop
- 转发/旁路:通过在指令执行过程中直接将数据从一个流水线阶段传递到另一个阶段
- 交换指令顺序
控制冒险
- 原因:指令的执行顺序被更改
- 转移: 分支, 循环
- 中断
- 异常
- 调用/返回
- 解决: 取多条指令
- 多个指令流
- 预取分支目标
- 循环缓冲器